
Businesses are generating vast amounts of information at an unprecedented rate. To glean insights, organizations need a robust and flexible data infrastructure, the datawarehouse.
Enter datawarehouses – the backbone of modern data analytics. This comprehensive blog post will delve into the depths of datawarehouses, exploring their definition, architecture, benefits, and best practices. Whether you’re a data enthusiast or a business professional seeking to leverage data for strategic advantage, this guide will equip you with the knowledge to harness the potential of datawarehouses.
This article is split into 3 parts:
- Part 1: What is a datawarehouse?
- Part 2: Understanding how datawarehouses work
- Part 3: Pricing of different Datawarehouses
At the end you should have a basic idea of what a datawarehouse is, how it works under the hood, and how the pricing is structured of the main cloud datawarehouse providers.
Part 1: What is a datawarehouse? #
A datawarehouse is a centralized repository that integrates data from various sources within an organization. It acts as a consolidated and structured storage solution that allows businesses to harmonize and organize their data in a consistent format. Unlike traditional transactional databases, which are optimized for day-to-day operations, datawarehouses are designed to support analytical queries and provide a comprehensive view of the organization’s data landscape.
The world’s most valuable resource is no longer oil, but data
Source: The Economist
Organizations across industries recognize data’s immense value in today’s digital landscape. Data-driven decision-making has become a strategic imperative for businesses aiming to gain a competitive edge. However, the sheer volume, variety, and velocity of data generated can pose significant challenges. Datawarehouses address this need by providing robust solutions for managing and analyzing large quantities of data across an organization. By consolidating data into a single source of truth, datawarehouses enable efficient data governance, integration, and analysis, empowering companies to extract meaningful insights and make data-backed decisions.
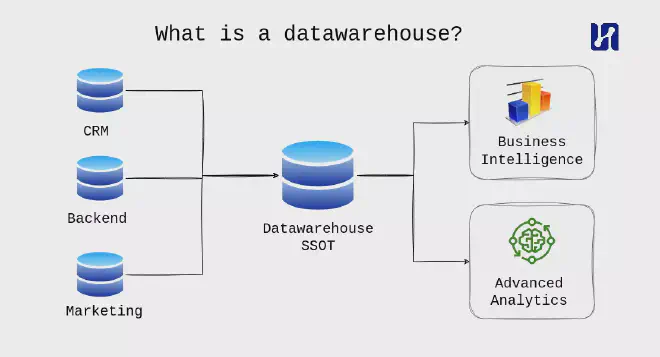
Create a Single source of truth #
Datawarehouses facilitate powerful analytics capabilities by providing a structured and optimized environment for querying and reporting. With the ability to store historical data, datawarehouses enable organizations to perform trend analysis, identify patterns, and make informed predictions. Moreover, by integrating data from disparate sources, such as operational systems, CRM platforms, marketing databases, and more, datawarehouses offer a holistic view of the business, facilitating cross-functional analysis and enabling stakeholders to derive insights from various data domains.
Enable Self-service BI with a Strong Foundation #
By establishing a single source of truth (SSOT) and developing a well-suited analytics database, you take the first step towards enabling self-service business intelligence (BI). It is crucial to avoid creating reports on an unreliable foundation, as this often leads to unusable outcomes. With a solid foundation, you can significantly reduce the barriers for everyone in your organization to access and utilize the available data.
Historical Analysis and Trend Identification Made Easy #
Moreover, a datawarehouse provides the capability for historical analysis and trend identification. Operational databases typically focus on updating records, which can pose challenges when analyzing past data. Storing data temporally with events allows you to track changes effectively over time. Your datawarehouse serves as an ideal platform for building a temporal view of your data, enabling historical analysis and trend identification with ease.
Empower Your People with Secure Data Access #
As you establish a SSOT, it is essential to consider data access control. Role-based access control (RBAC) and role inheritance play a vital role in this aspect, and many datawarehouses offer support for these features in various forms. Leveraging RBAC, you can create a role hierarchy with privilege inheritance, reflecting the organizational structure. This empowers you to implement and manage data democratization and data access intuitively, while maintaining the necessary security measures.
Accelerate Your Organization’s AI Capabilities #
To unlock the full potential of AI within your organization, a datawarehouse (or organized data lake) plays a pivotal role by enabling AI use cases in four critical ways:
- Leveraging Temporal Data: Successful AI implementations require access to temporal data. A datawarehouse empowers you to capture, store, and analyze data over time, enabling you to uncover meaningful insights, identify patterns, and make accurate predictions that drive informed decision-making.
- Unifying Diverse Data Sources: To maximize impact, it’s crucial to consolidate data from various sources into a single decision model. A datawarehouse acts as a central repository, seamlessly integrating data from disparate systems, databases, APIs, and more. This consolidation enhances data quality, facilitates cross-domain analysis, and enables the creation of comprehensive AI models.
- Harnessing Clean, High-Quality Data: The quality of your data directly impacts the accuracy and effectiveness of AI solutions. A datawarehouse serves as a hub for high-quality, cleaned data, ensuring that your AI algorithms are built on a solid foundation. By leveraging clean data, you can trust the insights generated by your AI systems and make well-informed decisions that drive tangible results.
- Understanding Data Trends: Before you can effectively leverage AI, it’s essential to gain a deep understanding of the trends and characteristics of your data. Building a datawarehouse provides a solid starting point for data exploration, enabling you to analyze data patterns, detect anomalies, and uncover hidden relationships. This foundational understanding sets the stage for advanced AI capabilities that deliver valuable insights and trans-formative outcomes.
Conclusion: The Power of Datawarehouses #
Datawarehouses play a pivotal role in today’s data-driven landscape, enabling organizations to gain valuable insights, enhance operational efficiency, identify market trends, seize growth opportunities, democratize data, and accelerate their AI capabilities. By leveraging datawarehouses effectively, businesses can harness the power of data to drive success.
Part 2: Understanding how datawarehouses work #
In this section, we delve into the architecture of datawarehouses and explore their internal workings.
Distinction Between OLAP and OLTP #
While operational databases are designed for online transactional processing (OLTP), datawarehouses are focused on online analytical processing (OLAP). One significant difference lies in the storage mechanism employed by datawarehouses, which often utilize columnar storage instead of row-based storage. It is important to choose the right tool for the job, as OLAP databases are not well-suited for handling OLTP workloads. This choice impacts the data loading process into the datawarehouse.
Separation of Compute and Storage for Scalability and Performance #
A widely adopted paradigm is the separation of compute and storage in data warehousing. This approach allows independent scaling of compute and storage resources, ensuring that organizations only pay for what they use, especially in cloud-based datawarehouses. By moving data to compute instead of the other way around, cloud datawarehouses and data lakehouse (see next paragraph on datalakes and lakehouses) technologies excel in handling analytical use-cases where the ability to process large amounts of data takes precedence over latency concerns. The dust has not yet settled on this matter; a popular technology is DuckDB, an in-process database suited for analytical queries. DuckDB is kind of the SQLite of OLAP, and while it is maybe not your typical datawarehouse, it does deserve to be mentioned here.
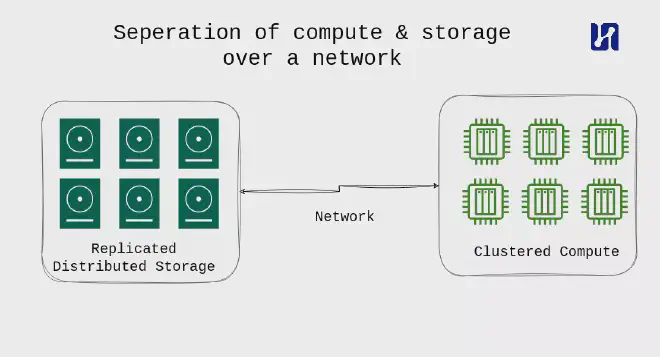
Centralized Data Storage #
Datawarehouses, and the emerging concept of a “data lakehouse,” typically store all data in a central location. This central location is often a cloud bucket, such as AWS S3, which serves as a robust storage hub. Data is loaded from the data lake into the datawarehouse, leveraging the simplicity and power of cloud storage. This setup has quickly risen in popularity, using the fact that cloud storage is very robust and very scalable.
Many people get confused with all the buzzwords in the data world nowadays, we often joke that a data lake is just a folder of files in the cloud.
Elevate Data Quality for Enhanced Analytics #
Achieving reliable and high-quality data is vital for unlocking the full potential of analytics. By implementing a well-defined data cleaning and modeling process within your datawarehouse, you can establish a Single Source of Truth (SSOT) that ensures data integrity and usability. Here’s how this process enhances your analytics capabilities:
- Data Cleaning for Accuracy: By systematically cleaning your data within the datawarehouse, you eliminate null values and remove duplicates. This ensures that your analytics are based on accurate, complete, and reliable data. Clean data enhances the accuracy of your insights, enabling you to make data-driven decisions with confidence.
- Tailored Data Modeling: The data modeling stage involves setting up a structure that aligns with your specific analytical goals. For business intelligence (BI) purposes, a common approach is adopting a star-schema data model. This model organizes data into a central fact table surrounded by dimension tables, simplifying query performance and enhancing data analysis efficiency. By tailoring the data model to your end goals, you optimize the analytics experience and streamline the extraction of valuable insights.
ELT: Extract, Load, Transform #
To create a datawarehouse, the first step is to extract data from various sources within your organization. Traditionally, this process involved hand-coding Python and shell scripts. However, there are now numerous tools available to simplify and streamline this task. One significant change in the data landscape is the shift from ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform). We have also covered this topic in our blog post on the Modern Data Stack, which you can find here.
There are generally two approaches to data extraction and loading. The first approach is to use ingestion tools like Airbyte and Meltano, which enable direct loading of data into the datawarehouse. These tools are efficient for quickly ingesting various types of data, such as Google Analytics tracking data and Salesforce CRM data. The second approach involves extracting data to a cloud bucket (often referred to as a data lake) through alternative means and then loading it into the datawarehouse using a native loader. This approach often offers the best performance characteristics. When designing your ETL process, an important aspect to consider is that datawarehouses are not optimized for online transactional processing (OLTP). This means that loading data in batches is usually faster, more cost-effective, and improves overall performance in the long run.
Once the data is loaded into the datawarehouse, the next step is data transformation. In the ELT paradigm, this transformation is typically performed in stages. At this stage, we can fully leverage the capabilities of the datawarehouse and utilize tools like dbt to assist in the data transformation process. Adopting dbt offers several advantages. Firstly, it allows us to avoid writing custom code by utilizing the expressive power of SQL. Additionally, we can take advantage of the scalability of the datawarehouse, eliminating the need to set up an Apache Spark cluster or similar infrastructure. Lastly, dbt provides benefits such as treating SQL more like code, enabling us to write reusable SQL queries and facilitating the implementation of tests for our transformations.
Part 3: Pricing of different Datawarehouses #
After delving into the details of datawarehouse architecture, let’s now explore the pricing options available for cloud datawarehouses. Understanding and evaluating costs and return on investment (ROI) is crucial before embarking on building a cloud datawarehouse.

In this section, we will compare the pricing options of a few major cloud datawarehouse providers. Our comparison includes Google BigQuery, AWS Redshift, Azure Synapse Analytics, and the cloud-agnostic datawarehouse solution, Snowflake.
Please note that this section will not cover OLAP databases designed for real-time analytics, such as Apache Druid, ClickHouse, and SingleStore. These databases serve a different use case, which we will discuss in a separate article. If you’re eager to jump straight to the conclusion in terms of pricing, we’ve provided a comprehensive table at the end.
Different pricing options #
Every database provider supports multiple pricing options. If we were to categorize them, the most important options are capacity-based pricing and serverless pricing. With capacity-based pricing, you pay for running a datawarehouse with certain specs, which can be mapped to a certain number of vCPUs and RAM that your datawarehouse has regarding compute capacity. The mapping is necessary because every cloud provider has its own way of defining the computing capacity of the datawarehouse.
All in all pricing of cloud datawarehouses is quite complex. This complexity could be deliberate, making it exceedingly challenging to compare prices among various datawarehouses. Take, for example, AWS Redshift, which offers five distinct pricing modes without including storage costs. For this reason, we won’t explore all the pricing options in this post, as they are also subject to change.
In serverless mode, you pay for every byte processed by the queries you run in your datawarehouse. Many datawarehouses are nowadays also ‘lake houses’, allowing them to directly run queries on your data lake (your storage buckets, like s3). This can be a great (cheap) option if you are just starting out, and have smaller datasets.
It’s crucial to recognize that not all cloud providers offer the level of flexibility you may desire. AWS serves as a typical example, particularly in their database offering. At the lower end, the smallest tier database available is the ‘dc2.large’ with 2 vCPUs. However, the next tier up is the ‘dc2.8xlarge,’ which is a staggering 18 times more expensive. Next up, we look at the pricing models, in detail, per solution.
Azure synapse analytics Pricing #
Azure Synapse Analytics offers two pricing options: serverless and dedicated. In serverless mode, you are charged $5 per terabyte (TB) processed, while dedicated mode requires upfront payment for reserved compute resources. Here are further details:
- Dedicated options: Dedicated pricing is based on service levels, starting with the DW100c option. It costs $1.51 per hour and provides 60GB of memory and approximately 4 vCPUs.
- Serverless processing: For serverless mode, the cost is $5 per TB processed.
- Storage costs: Azure Synapse Analytics charges $23 per TB per month for storage.
BigQuery Pricing #
BigQuery pricing consists of storage and compute components. Here’s a breakdown:
- On-demand pricing: You pay per TB processed, with the first TB per month being free. Subsequently, it is $5 per TB.
- Capacity pricing: This model charges for the compute capacity you reserve for query processing. It supports dynamic auto-scaling and slot commitments. Each slot represents a virtual CPU that BigQuery uses to execute SQL queries. The cost per slot is $0.044 per hour (for a standard account). Increasing the number of slots enhances the datawarehouse’s ability to handle concurrent and heavy queries. A downside is that the slot commitment model can be complex, and there is a minimum number of slots that has to be committed to.
- Storage costs: The cost is $20 per TB, with a reduction of approximately 50% for data that hasn’t been accessed in 90 days.
One thing that BigQuery does very well, is that it offers a significant advantage with its serverless architecture, eliminating the need to configure instances, sizes, or VMs manually. Downside of course is that you lose the flexibility of tuning this yourself.
Amazon Redshift Pricing #
Amazon Redshift pricing offers several options, including on-demand instances, Redshift Serverless, and Redshift Spectrum. Key details include:
- On-demand instances: You pay per hour for running instances. For example, a dc2.large instance with 2 vCPUs and 15GB of memory costs $0.324 per hour.
- Amazon Redshift pricing is based on a few options, the main ones are: On-demand instances, Redshift Serverless or Redshift Spectrum pricing. With on-demand instances you pay per hour for running instances, while with Redshift serverless you pay while your datawarehouse is running when you query it, with Redshift Spectrum you pay per byte processed by your queries.
- Storage costs: There are several options here, but at a flat rate your storage costs $25.60 per month.
Redshift pricing has so many components that we have kept it short here. Take a look at the example comparisons below to get an idea.
Snowflake Pricing #
Snowflake pricing is based on three main components: storage cost per terabyte, the price for running virtual warehouses in credits per hour, and the account type determining the credit price. Here’s an overview:
- Virtual warehouses: Snowflake provides different tiers of virtual warehouses, ranging from X-small to Medium to 6X-large. These tiers cost 1, 4, and 512 credits per hour, respectively. The price per credit for a standard account is $2.60.
- On-demand: While Snowflake doesn’t offer a pay-per-byte processed model, it provides a useful feature that automatically suspends virtual warehouses when they’re idle for 10 minutes. However, there is a drawback to this feature. When a virtual warehouse is suspended, it requires startup time before it can process queries again. As a result, users may experience longer query response times. According to Snowflake documentation, starting a warehouse usually takes only a few seconds, but in rare cases, it may take longer as Snowflake provisions the necessary compute resources. This delay may not be acceptable in many scenarios.
- Storage: Snowflake offers two storage options. You can choose to pay for on-demand pricing, which is more expensive per terabyte, or opt for upfront payment, providing discounted pricing. In our example below, upfront payment for storage is used, approximately half the price of on-demand storage pricing.
Example pricing comparison #
Here is a quick overview of the main pricing options for the different cloud providers:
| Storage (1TB) / Month | Capacity-based Compute costs | Serverless Compute costs | Note | |
|---|---|---|---|---|
| Snowflake | $45 | $2.60 / credit hour | - | Snowflake doesn’t support a serverless mode. |
| BigQuery | $20 | $0.044 / slot hour | $6 / TB | |
| Redshift | $25.60 | $0.324 / hour (dc2.large) | $5.00 / TB | |
| Azure Synapse Analytics | $23 | $1.51 / hour (DW100c) | $5 / TB |
Next, we compare the costs to run a typical (small-sized) cloud datawarehouse for business intelligence purposes. In this comparison, we compare (as representative as possible)** Snowflake, Redshift, Azure Synapse Analytics, and Google BigQuery with the following attributes:
- 4 vCPU’s and 32GB of RAM
- 1TB storage
- For 10 hours per day and 20 days per month, for a total of 200 hours per month (26% of the time)
(We try to make an as close as possible comparison; this is not always easy because not every provider explains how many vCPUs or RAM you get with their tiered models.)
The table below displays the costs of running this setup for one month per cloud provider:
| Storage (1TB) | Loading Costs | Usage Costs | Total | |
|---|---|---|---|---|
| Snowflake | $45 | $403 | $2080 | $3040.50 |
| BigQuery | $20 | Free | $281 | $301 |
| Redshift | $25.60 | $20.00 | $129.60 | $175.20 |
| Azure Synapse Analytics | $23 | Free | 302$ | $325 |
In our previous example, we looked at running our datawarehouse for ~26% of the time. This is a great way to save money if applicable. This is not always the case: In many situations, you will want your warehouse to run constantly. An example of this could be a mobile application with embedded analytics with active users at all times of the day. This will significantly drive up your costs.
Note that our comparisons do not consider some of the more intricate details when considering your cloud datawarehouse costs, like data transfer costs. There are also several ways to optimize your cloud datawarehouse costs, like buying commitments for longer periods.
Datawarehouse Pricing Conclusions #
In summary, when considering your options surrounding the pricing of datawarehouses, it is generally recommended to stick with the datawarehouse provided by your cloud provider to save time, money, and avoid the complexity of data migration between clouds. Otherwise, Snowflake can be deployed in one of the clouds of your choosing, which is a market leader and definitely enterprise ready, but more costly.
Among the three major cloud providers (excluding Snowflake), BigQuery stands out as a prominent player in the cloud datawarehouse space. It offers unique features and is Google’s flagship product. Notably, BigQuery’s compute pricing model provides advantages such as flexibility with on-demand pricing for small loads and dynamic allocation of slots. This flexibility helps optimize costs and aligns with the serverless promise of the cloud. Additionally, BigQuery automatically addresses the need for handling both small concurrent queries and occasional heavy queries, making it a user-friendly choice.
While Snowflake offers solutions such as suspending datawarehouses, it doesn’t provide the same level of ease and convenience as BigQuery. Snowflake’s industry-leading position and enterprise focus make it a preferred option in certain scenarios, but for most users, leveraging the features and benefits of the datawarehouse provided by their cloud provider is a more sensible choice.
Cloud datawarehouse vs On-premise datawarehouse #
This article wouldn’t be complete without considering the different deployment options for your data warehouse. In practice, it often makes sense to use the cloud options there are, but it is definitely worth exploring the trade-offs. Below we have listed the main trade-offs for using a cloud data warehouse:
1. Auto Scaling: One significant advantage of cloud datawarehouses is their ability to automatically scale resources up or down based on demand. This scalability ensures that the datawarehouse can handle varying workloads efficiently without manual intervention. In contrast, on-premise datawarehouses often require upfront capacity planning and resource allocation, which can result in either underutilization or performance bottlenecks during peak periods.
2. Flexible Pricing: Cloud datawarehouses typically offer flexible pricing models that align with usage patterns. They often provide options for pay-as-you-go or consumption-based pricing, allowing organizations to scale their costs based on actual usage. This flexibility enables better cost optimization, especially for organizations with fluctuating workloads. On the other hand, on-premises datawarehouses require significant upfront investments in hardware, software licenses, and maintenance, making them less adaptable to changing business needs.
3. More Expensive: While on-premises datawarehouses may have lower initial setup costs, they can become more expensive in the long run due to hardware upgrades, maintenance, and ongoing operational expenses. In contrast, cloud datawarehouses eliminate the need for hardware procurement, infrastructure management, and associated costs. The pay-as-you-go model of cloud datawarehouses ensures that organizations only pay for the resources they actually consume, making it a more cost-effective option for many businesses.
4. Fully Managed: Cloud datawarehouses are typically fully managed services provided by cloud providers. This means that the cloud provider handles infrastructure provisioning, software updates, security, and performance optimization. On-premises datawarehouses, on the other hand, require dedicated IT teams to manage hardware, software installations, patches, upgrades, and overall system maintenance. The burden of managing the infrastructure and ensuring its availability rests on the organization’s IT staff.
5. Uptime Guarantees: Cloud datawarehouses often come with service level agreements (SLAs) that guarantee high availability and uptime. Cloud providers invest in robust infrastructure and redundancy measures to ensure minimal downtime. In contrast, on-premise datawarehouses rely on the organization’s IT infrastructure, and downtime risks are primarily managed by the organization itself. Achieving high availability in on-premises environments often requires significant investments in redundant hardware, failover systems, and disaster recovery plans.
6. Proprietary Software: Cloud datawarehouses typically utilize proprietary software developed by the cloud provider. These solutions are specifically designed to take advantage of the cloud infrastructure and provide optimized performance, scalability, and security. On-premises datawarehouses, on the other hand, may utilize a combination of commercial and open-source software, requiring organizations to manage integration, compatibility, and potential licensing costs.
Overall, cloud datawarehouses offer advantages such as auto scaling, flexible pricing, managed services, uptime guarantees, and proprietary software that streamline operations and are cost-efficient. However, organizations should evaluate their specific requirements, compliance needs, data sovereignty concerns, and long-term costs before deciding between cloud and on-premises datawarehouses.
Conclusion #
Datawarehouses play a crucial role in today’s data-driven world, providing organizations with the infrastructure needed to store, manage, and analyze large amounts of data. By consolidating data from various sources into a single source of truth, datawarehouses enable powerful analytics capabilities, historical analysis, trend identification, and self-service business intelligence. They empower organizations to make data-backed decisions, optimize operational efficiency, understand customer behavior, and unlock the full potential of AI.
The architecture of datawarehouses involves separating compute and storage, utilizing a central data storage location, and implementing data cleaning and modeling processes to enhance data quality. The adoption of ELT (Extract, Load, Transform) methodologies and tools like dbt simplifies the data extraction, loading, and transformation processes, enabling efficient data integration and transformation within the datawarehouse.
When considering datawarehouses, it’s important to evaluate the pricing options offered by different cloud providers. Capacity-based pricing and serverless pricing models are commonly used, with each option having its own advantages and considerations. Azure Synapse Analytics, Google BigQuery, and Amazon Redshift are popular datawarehouse solutions, each with its own pricing structure and features.
Overall, datawarehouses empower organizations to harness the power of data, gain actionable insights, and drive business success in today’s data-driven landscape. By investing in robust datawarehouse infrastructure and adopting best practices, businesses can unlock the true potential of their data and stay ahead in a competitive market.